习惯的力量强大却往往无法察觉。往往不经意之间,陷入习惯的陷阱中却不自知。
在我们的项目中,为了能够保存分析报表以及用户设置的报表查询条件,我们将这些信息视为报表元数据存储在MongoDB中。要存储的元数据包括:
- 报表分类(ReportCategory)
- 报表(Report)
- 报表查询条件(QeuryCondition)
一个报表分类会包含多个报表,同一个报表只能属于一个分类。每个报表提供了多个标准查询条件和多个用户自定义查询条件。
我需要为这些元数据设计MongoDB的DB Schema。最初考虑将这三个概念合起来定义为元数据表的一条记录。之后想到对于一个报表而言,需要频繁对报表的查询条件进行增删操作,似乎又应该将查询条件单独分离出来。那么报表分类与报表呢?是否将报表也独立出来才合适?对于MongoDB这样的Document数据库而言,将Report作为ReportCategory的embedded属性也是可行的,至少不会像关系型数据库那样会产生数据冗余。倘若要分开,当需要查询某个分类下的所有报表时,还得多余地做一次Link。
好纠结啊!似乎怎么设计都是可行的,又仿佛总有不如意处。
正在思索中,突然想起对于这样面向文档的NoSQL数据库而言,使用聚合(Aggregate)来观察表记录会更加恰当。这个想法恍若闪电般迅捷而锐利,猛地撞向脑中的思绪,一下子点燃了我的设计思维。
这里所谓“聚合”,非面向对象中表达对象关系的概念,而是领域驱动设计(DDD)对对象边界的思考。关于聚合(Aggregate)的设计,我根据过往的经验,整理出五条设计原则:
- 聚合作为一种边界,主要用于维护业务完整性,此时应遵循业务规则中定义的不变量(Invariant)
- 作为聚合边界内的非聚合根实体对象,若可能被别的调用者单独调用,则应该作为单独的聚合分离出来
- 在聚合边界内的非聚合根对象,与聚合根之间应该存在直接或间接的引用关系,且可以通过对象的引用方式;若必须采用Id来引用,则说明被引用的对象不属于该聚合
- 若一个对象缺少另一个对象作为其主对象就不可能存在,则该对象一定属于该主对象的聚合边界内
- 若一个实体对象,可能被多个聚合引用,则该实体对象应首先考虑作为单独的聚合
这些设计原则都是我在探索聚合设计时的一些思考,多次实践下来,窃以为颇有指导价值。这里不再铺开,留待以后的文章详述。单说本例,我们该如何运用这些原则来思考ReportCategory、Report与QueryCondition之间的关系?
显然,套用这些原则,我认为前面纠缠不清的混乱思路已可迎刃而解。从业务完整性看,Report虽属于ReportCategory,但二者未尝有强的约束关系,即不存在业务上的不变量(Invariant)。例如ReportCategory可以没有Report,成为一个空的分类,我们也可以撇开ReportCategory,单独查询所有的Report。倘若我们将Report放到ReportCategory聚合中,由于Report可能会被单独调用,聚合的边界保护反而成为了障碍,不合理。
于是,我们可以得出第一个结论:ReportCategory和Report应该属于两个不同的聚合。
基于第四条原则,我们可以提出问题:当QueryCondition缺少Report对象后,还有存在意义吗?答案一目了然,没有Report,就没有QueryCondition。皮之不存毛将焉附!第二个结论自然得来:Report与QueryCondition应属于同一个聚合。于是,模型呼之欲出:
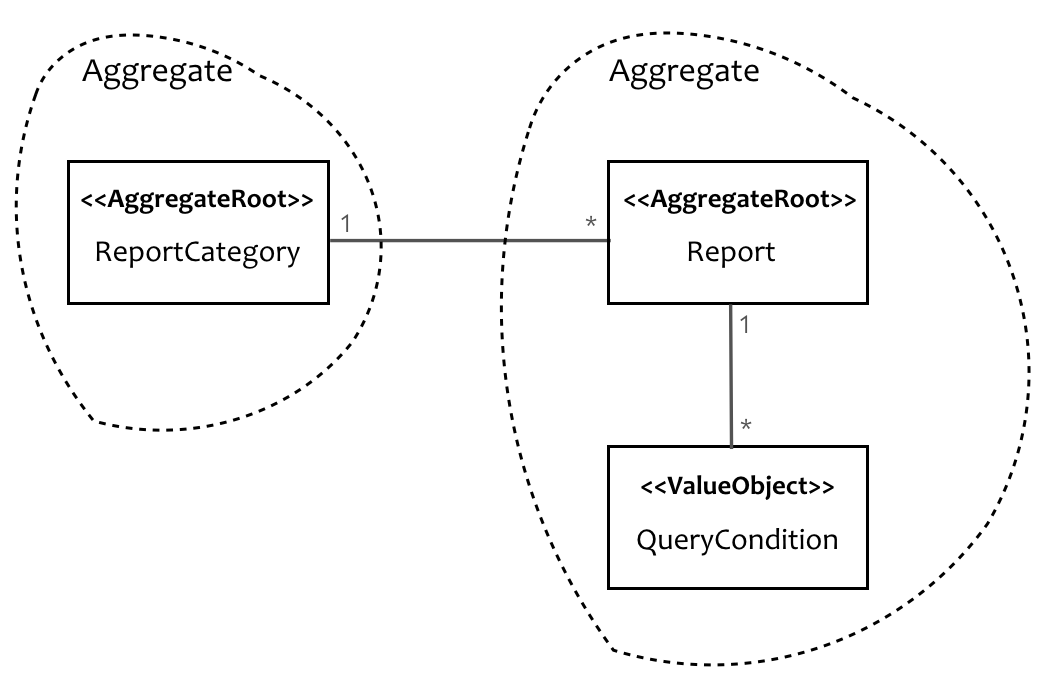
上图是领域模型而非数据模型。站在领域驱动设计的角度,这才是正确的打开姿势。那么,使用该领域模型去指导MongoDB的Schema设计,是否有将领域混入技术实现之嫌呢?从设计方向看,先考虑领域模型才是正解,DB的技术实现应为了满足该领域模型而设计。只有当领域模型可能阻碍技术实现,又或者依据领域模型得到的Schema设计不满足性能或其他质量属性需求时,才应该反过来调整领域模型。对于MongoDB这种面向Document的数据库,以聚合概念指导Schema设计,可谓水到渠成,不仅没有违和之感,反而让Repository的实现变得更加简单、自然。
在项目开发过程中,我先入为主地做了技术选型,从而习惯性地开始针对MongoDB进行Schema设计,反而忘了领域驱动设计的指导原则。技术人员对技术实现往往见猎心喜,因而忽略了领域设计的驱动力,慎之慎之!