
当我们将对象的行为看作职责时,就赋予了对象的生命与意识,使得我们能够以拟人的方式对待对象。一个聪明的对象是对象自己知道应该履行哪些职责,拒绝履行哪些职责,以及该如何与其他对象协作共同履行职责。这时的对象绝不是一个愚笨的数据提供者,它学会了如何根据自己拥有的数据来判断请求的响应方式、行为的执行方式,这就是所谓的对象的“自治”。
我在《领域驱动战略设计实践》中提及了限界上下文的自治特性,事实上,从更小的粒度来看,对象仍然需要具备自治的这四个特性,即:
- 最小完备
- 自我履行
- 稳定空间
- 独立进化
最小完备
如何来理解对象的“最小完备”?John Kern谈到对象的设计时,提到:“不要试着把对象在现实世界中可以想象得到的行为都实现到设计中去。相反,只需要让对象能够合适于应用系统即可。对象能做的、所知的最好是一点不多一点不少。”因此,对象的最小完备取决于该对象具备的知识,恰如其分地履行职责。不放弃该自己履行的职责,也不越权对别人的行为指手画脚。
例如,我们需要设计一个Web服务器,它提供了一个对象HttpProcessor,能够接收由HttpConnector发送来的Socket请求,并在处理请求后返回响应消息。请求和响应被定义为HttpRequest和HttpResponse类。请求的处理过程中需要对Socket消息进行解析,这个解析职责应该分配给哪个对象呢?
如果我们将解析职责完全交给HttpProcessor来完成,那么HttpRequest和HttpResponse将沦为两个仅提供数据的“哑对象”,这就违背了自治原则,没有满足对象职责的完备性。如果我们将对请求和响应的解析工作完全放到各自的HttpRequest与HttpResponse对象中,似乎又超出了这两个对象的能力范围。仔细分析解析过程,解析Socket消息获得请求头和请求体,实际上等同于是创建HttpRequest对象,这个职责显然不应该交给HttpRequest。然而,在解析请求时,还涉及一些系统开销大的字符串操作或其他操作,这些请求参数并不是Servlet所必须要的。也就是说,服务端的HttpProcessor在接收到请求后,并没有必要处理全部的请求参数,因为它的职责是快速响应请求,不应该将时间浪费在大量目前并不需要的请求消息上。这时,就可以将这些不曾解析的消息直接赋给HttpRequest与HttpResponse。由于二者都拥有了这些信息,就可以提供解析它们的职责:
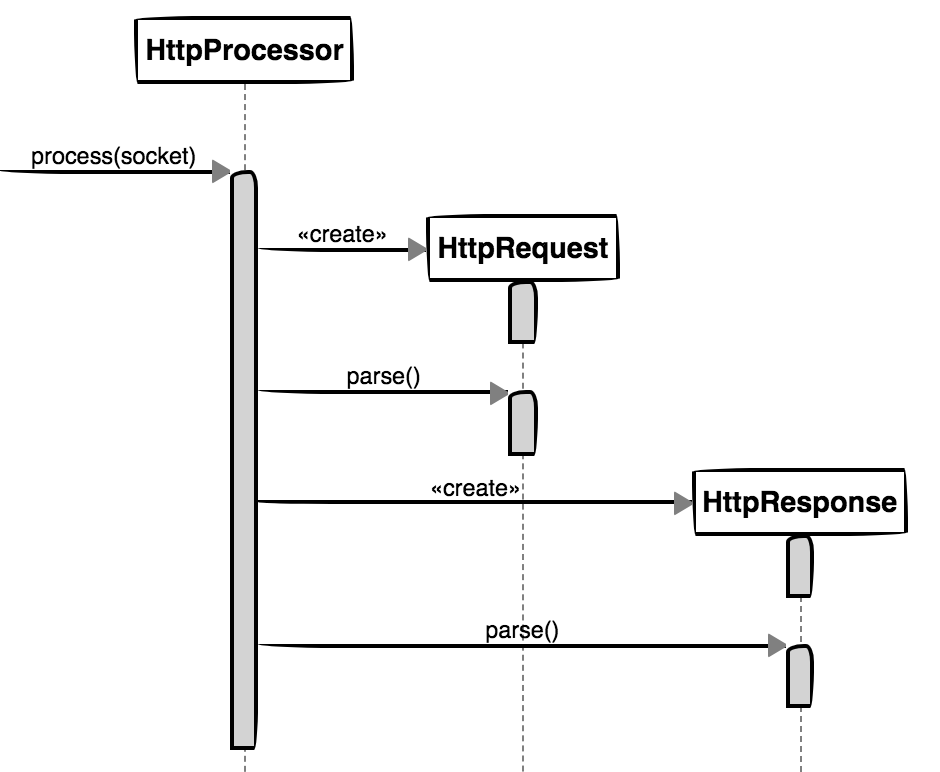
遵循最小完备原则,使得HttpProcessor、HttpRequest与HttpResponse三者之间的权责变得更加清晰。此外,这一设计方式还有利于改善性能。由于解析开销较大的字符串操作并未由HttpProcessor承担,而是将这些数据流塞给了HttpRequest与HttpResponse,使得HttpProcessor的process()操作可以快速完成。当请求者真正需要相关请求信息时,就可以调用HttpRequest与HttpResponse对象的parse()方法。
自我履行
所谓“自我履行”就是对象利用自己的属性完成自己的任务,不需要假手他人。这也是“信息专家模式”的体现,即信息的持有者即为操作该信息的专家。只有专业的事情交给专业的对象去做,对象的世界才能做到各司其职、各尽其责。Martin Fowler提到的“特性依恋(Feature Envy)”坏味道就违背了对象的自我履行原则,只是二者的立场不同。特性依恋是指在一个对象的行为中,总是使用别的对象的数据和特性,就好像是羡慕别人拥有的好东西似的。自我履行指的是我守住自己的一亩三分地,该自己操作的数据绝不轻易交给别人。
例如在一个报表系统中,需要根据客户的Web请求参数作为条件动态生成报表。这些请求参数根据其数据结构的不同划分为三种:
- 单一参数(SimpleParameter):代表key和value的一对一关系
- 元素项参数(ItemParameter):一个参数包含多个元素项,每个元素项又包含key和value的一对一关系
- 表参数(TableParameter):参数的结构形成一张表,包含行头、列头和数据单元格
这些参数都实现了Parameter接口,该接口的定义为:
public interface Parameter { |
在报表的元数据中已经配置了各种参数,包括它们的类型信息。服务端在接收到Web请求时,通过ParameterGraph加载配置文件,并利用反射创建各自的参数对象。此时,ParameterGraph拥有的参数都没有值,需要通过ParameterController从ServletHttpRequest获得参数值对各个参数进行填充。代码如下:
public class ParameterController { |
显然,这三种参数对象没有能够做到自我履行,它们把自己的数据“屈辱”地交给了ParameterController,却没有想到其实自己才是拥有填充请求数据能力的对象,毕竟只有它们才最清楚各自参数的数据结构。如果让这些参数对象都变为能够自我履行的自治对象,Do it myself,情况就完全不同了:
public class SimpleParameter implements Parameter { |
当参数自身履行了填充参数的职责时,ParameterController履行的职责就变得简单了:
public class ParameterController { |
这时,我们发现各种参数由于数据结构结构的不同,导致填充行为的差异,但从抽象层面看,都是将一个ServletHttpRequest填充到Parameter中。如果将fill()方法提升到Parameter接口中,哪里还需要分支语句进行类型判断与类型转换呢?
public class ParameterController { |
当一个对象能够自我履行时,就可以让调用者仅仅需要关注对象能够做什么(what to do),而不需要操心其实现细节(how to do),从而将实现细节隐藏起来。当我们让各种参数对象都履行填充职责时,ParameterController就可以只关注抽象的Parameter提供的公开接口,而无需考虑实现,对象之间的协作就变得更加松散耦合,对象的多态能力才能得到充分地体现。
稳定空间
一个自治的对象具有稳定空间,使其具备抵抗外部变化的能力。要做到这一点,就需要处理好外部对象与自治对象之间的依赖关系。方法就是遵循“高内聚松耦合”原则来划分对象的边界。这就好比两个行政区,各自拥有一个居民区和一家公司。居民区A的一部分人要跨行政区到公司B上班,同理,居民区B的一部分人也要跨行政区到公司A上班:
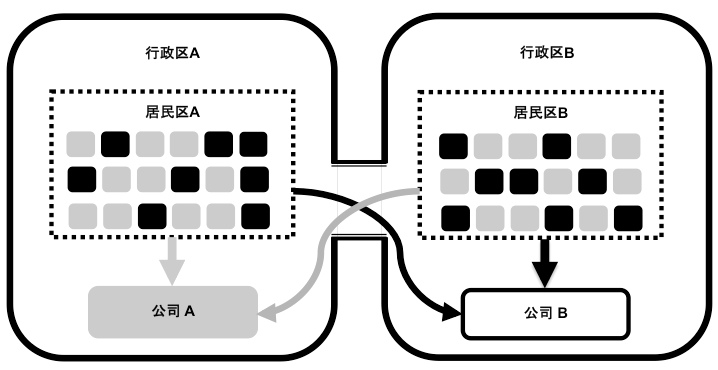
这样的两个行政区是紧耦合的,因为居民区与公司之间的关系没有做到高内聚,只是一种松散随意的划分。现在我们按照居民区与公司之间的关系,对居民区的人重新调整,就得到了两个完全隔离的行政区:
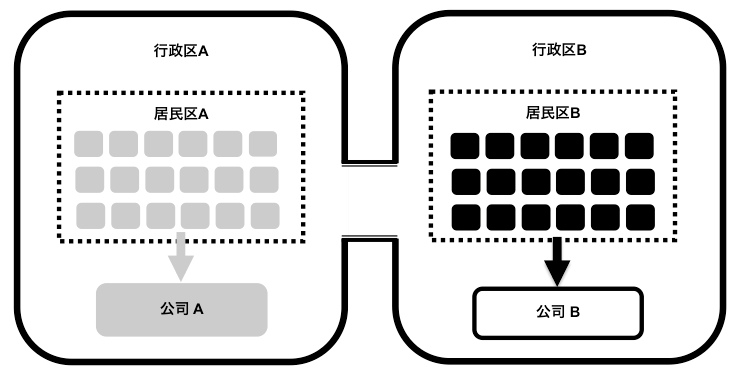
在这个例子中,调整后的系统并没有改变任何本质性的事情。所有的人都还在原来的公司上班,没有人失业;没有人流离失所,只是改变了居住地。但仅仅由于居民居住区域的改变,两个行政区的依赖关系就大为减弱。事实上,对于这个理想模型,两个行政区之间已经没有任何关系,它们之间桥梁完全可以拆除。这就是“高内聚松耦合”原则的体现,通过将关联程度更高的元素控制在一个单位内部,就可以达到降低单位间关联的目的。
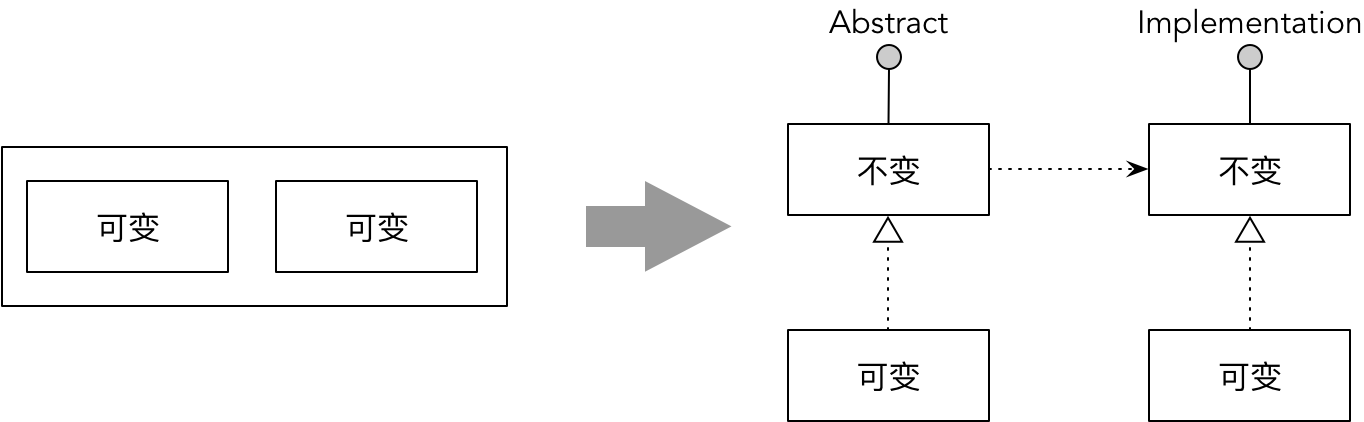
要实现自治对象的稳定空间,还需要识别变化点,对变化的职责进行分离和封装。实际上,许多设计模式都可以说是“分离和封装变化”原则的体现。例如,当我们发现一个对象包含的职责既有不变的部分,又有可变的部分,只是就可以将可变的部分分离出去,将其抽象为一个接口,再以委派的形式传入到原对象,如下图所示:

此时抽象出来的接口IChangable其实就是策略模式(Strategy Pattern)或者命令模式(Command Pattern)的体现。例如Java线程的实现机制是不变的,但运行在线程中的业务却随时可变,将这部分可变的业务部分分离出来,并抽象为Runnable接口,再以构造函数参数的方式传入到Thread中:
public class Thread ... { |
模板方法模式(Template Method Pattern)同样分离了不变与变,只是分离变化的方向是向上提取为抽象类的抽象方法而已:
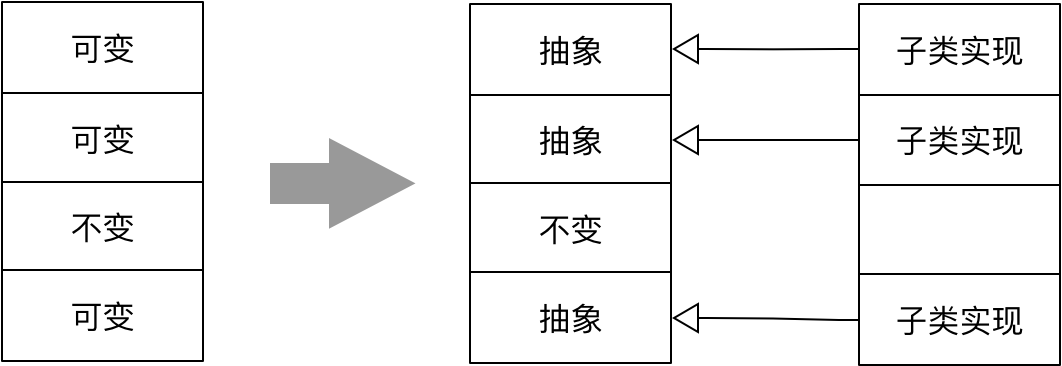
例如授权认证功能的主体是对认证信息token进行处理完成认证。如果通过认证,则返回认证结果,认证无法通过,就会抛出AuthenticationException异常。整个认证功能的执行步骤是不变的,但对token的处理需要根据认证机制的不同提供不同实现,甚至允许用户自定义认证机制,就需要对这部分可变的内容进行抽象。AbstractAuthenticationManager是一个抽象类,定义了authenticate()模板方法:
public abstract class AbstractAuthenticationManager { |
该模板方法调用的doAuthentication()是一个受保护的抽象方法,没有任何实现。这就是可变的部分,交由子类完成实现。例如ProviderManager子类就实现了doAuthentication()方法:
public class ProviderManager extends AbstractAuthenticationManager { |
如果一个对象存在两个可能变化的职责,则违背了“单一职责原则”,即“引起变化的原因只能有一个”。分离这两个可变的职责,且分别进行抽象,然后再形成这两个抽象职责的组合,就是桥接模式(Bridge Pattern)的体现:
例如在实现数据权限控制时,需要根据解析配置内容获得数据权限规则,然后再根据解析后的规则对数据进行过滤。需要支持多种解析规则,同时也需要支持多种过滤规则,这时就不能将这两个可变的职责放到同一个类或者接口中,如下定义:
public interface DataRuleParser { |
分离规则解析与数据过滤职责,定义到两个独立的接口中。在数据权限控制功能中,过滤数据才是实现数据权限的目标,因此应以数据过滤职责为主,在实现类中,将规则解析器作为参数传入:
public interface DataFilter<T> { |
GradeDataFilter是过滤规则的一种,至于在过滤数据时,究竟选择什么解析模式,则取决于通过构造函数参数传入的DataRuleParser接口的具体实现类型。无论解析规则怎么变,只要不修改接口定义,就不会影响到GradeDataFilter的实现。
独立进化
稳定空间针对的是外部变化对自治对象产生的影响,独立进化关注的则是自治对象自身变化对外部产生的影响。二者是开放封闭原则(Open-closed Principle)的两面:若能对扩展开放,当变化发生时,自治对象就不会受到变化的影响,因为可以通过抽象进行扩展或替换;若能做到对修改封闭,只要对外公开的接口没有变化,封装在内部的实现怎么变化,都不会影响到它的调用者。这就将一个自治对象分为了内外两个世界,合理的封装是包裹在自治对象上的一层保护膜,对外公开的接口是自治对象与外部世界协作的唯一通道。注意,这里的“接口”并非语法意义上的interface,而是指代一种“交互”,可以是类型或方法的定义,即一切暴露在外面的信息,如下图所示:
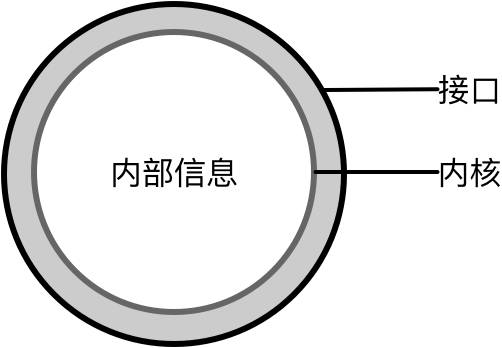
要做到独立进化,就是要保证自治对象的接口不变,这样才不会影响外部的调用者;做好了这一层保护,位于内核部分的内部信息就可以随意调整了。
要如何才能做到对内核的保护呢?其一是保证接口的稳定性,即避免对公开方法的参数和返回值的修改。例如我们定义一个连接FTP服务器的接口。倘若采用如下形式:
public interface FtpConnector { |
倘若在未来,连接功能需要增加一个新属性:服务器主路径homePath,则connect()方法就需要修改,或者新增加一个重载的方法。为了保证接口的稳定性,应尽量将一组内聚的参数封装为对象,只要对象类型没有变化,即使增加了新的属性和行为,也不会影响到已有的消费者。例如通过引入FtpServer类对ftp地址、端口、用户名和密码这几个内聚的概念进行了封装,则接口就可以定义为:
public class FtpServer { |
如果修改了FtpServer的定义,增加了一个新的属性,connect(ftpServer)接口的定义并不需要做任何调整。
数据结构和数据类型也需要进行合理的封装。这里要认识到在重复性上调用与实现的区别。遵循DRY(Don’t Repeat Yourself)原则,任何功能的实现应该只有一份,但对该功能的调用却会出现多份。这也正是在定义一个类时,为何需要为字段提供访问方法的原因。如果公有类暴露了它的数据字段,要想在将来改变字段的访问方式就非常困难,因为该字段的调用方法已经遍布各处,修改成本非常大。
工厂方法实则也体现了这一区别,即创建的实现逻辑只有一份,但创建对象的调用代码却可能分布在多处。假设没有工厂方法对创建逻辑进行封装,若创建对象的逻辑非常复杂,就会导致创建对象的调用代码出现大量重复;若创建对象的逻辑发生变化,由于重复出现调用代码的缘故,就需要修改多处。例如Java JDK中的EnumSet类,就通过工厂方法封装了EnumSet的创建逻辑。因为要考虑到创建对象的性能,JDK通过判断底层枚举类型的大小,来决定返回RegularEnumSet或JumboEnumSet实例,二者都是EnumSet的子类:
public abstract class EnumSet<E extends Enum<E>> ... { |
《Effective Java》在讲解这个案例时,认为:“这两个实现类的存在对于客户端来说是不可见的。如果RegularEnumSet不能再给小的枚举类型提供性能优势,就可能从未来的发现版本中删除,不会造成不良的影响。同样地,如果事实证明对性能有好处,也可能在未来的发行版本中添加第三甚至第四个EnumSet实现。客户端永远不知道也不关心他们从工厂方法中得到的对象的类;他们只关心它是EnumSet的某个子类即可。”显然,工厂方法的封装就使得调用者不再受到创建逻辑变化的影响,从这个角度来讲,EnumSet就是可以独立进化的。
倘若数据的类型在未来可能发生变化,也可以引入封装进行内外隔离,使得数据类型也可以独立进化。例如在一个BI产品中,诸如DataSource、DataSet、Field、Report、Dashboard、View等元数据都有其唯一标识。这些元数据信息存储在MySQL中,唯一标识采用数据库的自增长ID,则定义其为Int类型。在实现时,我们利用了Scala语言的特性,通过type关键字定义唯一标识,如:
object Types { |
在需要使用唯一标识的地方,我们使用了ID而非Int类型,例如操作数据集的方法:
object DataSets extends JsonWriter { |
不只是DataSet的唯一标识,DataSource、Report、Dashboard等的唯一标识皆使用了ID类型。在最初看来,这一设计不过是封装原则的体现,并未刻意考虑对未来变化的隔离。然而不曾想到,后来客户希望产品能够支持元数据迁移的功能。由于之前的设计使用了数据库的自增长标识,这就意味着该标识仅仅在当前数据库中能够保持其唯一性,一旦元数据迁移到了另外一个环境,就可能引起唯一标识的冲突。为了避免这一冲突,我们决定将所有元数据的唯一标识类型修改为UUID类型,并在数据表中定义为varchar(36)类型。由于我们事先定义了ID类型,有效地隔离了变化,仅需要修改数据库脚本,并重新生成了采用UUID为唯一标识的元数据模型对象,而大量的调用代码完全不受影响。