都说“过早进行性能优化是万恶之源”,我宁肯相信这是为了“矫枉过正”而出此惊人之语,更何况,现在的IT时代已与Donald Knuth的时代已有很大差异了。重点还是在于“过早”这个词,之所以Knuth告诫我们不要过早进行性能优化,原因在于:
- 判断性能是否存在问题,不能太早
- 太早做性能优化,有可能并没有弄清楚性能瓶颈在哪里

图为Donald Knuth在斯坦福大学计算机科学William Gates大楼的办公室
最近,我的团队成员正在着力于提高实时流处理任务的性能。由于客户为我们的测试环境仅提供了极度可怜的集群资源,我们需要在“螺蛳壳里做道场”,死扣性能,尽可能在方案与实现上将性能提升到极致。(顺带说,在测试时,不要奢侈地提供大量资源,反倒有可能尽早发现性能问题,从而让团队想办法解决之。)
一开始,我们想到的方案是增加Flink Streaming Job每个算子或算子链的并行度。Flink支持多个级别设置并行度,包括:
环境级别:对Execution Environment进行
parallelism的设置客户端级别:客户端提交Job时通过命令参数-p进行设置
算子级别:调用每个算子的
setParallelism()方法设置算子的并行度,在为算子设置并行度时,需要考虑它对算子链的影响。如果相邻算子的并行度不一样,两个算子就不能成为算子链。算子链可以减少不必要的线程切换,减少不必要的序列化和反序列化操作,减少延迟提高吞吐能力,因此,如果两个算子相邻,且中间没有数据的shuffle操作,应保证它们的并行度是相同的。
如果没有显式设置并行度,Flink的系统默认并行度为1。不同级别优先级不同,优先级按照高低,顺序依次为:
算子级别 -> 客户端级别 -> 环境级别 -> 系统默认级别
Flink的并行度设置并不是说越大,数据处理的效率就越高,而是需要设置合理的并行度。并行度的设置数量取决于Task Manager的数量以及slot数量。通常可以认为Task Manager部署的节点有多少核CPU,就有多少个slot。
设置了合理的并行度,就能有效地利用Worker节点的资源。但为何在实现之初,没有考虑并行度呢?原因在于引入并行度后,从上游传入的数据就会被Task Manager分配到不同的slot做并行处理,由于不同任务执行时间不同,slot的执行效率也可能不同,就可能无法保证同类数据多条数据的时序性。
为了保证同类数据的执行时序性,我们引入了Flink的keyBy算子。它能够将相同key的元素散列到一个子任务中,且没有改变原来的元素数据结构。keyBy使用的key应使用数据的主键,即ID,如此就能保证拥有相同ID值的同类数据一定执行在同一个子任务中,进行同步处理,这就保证了数据处理的时序性。时序性与并行度带来的高性能,就能鱼与熊掌兼得了。
即便如此,我们提升的性能依旧有限,毕竟受到资源的限制,我们不能盲目增大并行度。由于单条消息数据的处理逻辑非常复杂,它的处理能力已经达到我们能够优化的极限。最后,评估任务的处理能力,仅能做到每秒处理6条左右的数据,这一结果自然不能接受。一种立竿见影的手段是增加更多的资源,但我们还是想在没有更多资源支持下,看看能否竭尽所能提升性能。——这时,我们才想到去探索性能瓶颈到底在哪里?
我们开始监控实时流任务的执行,通过日志记录执行时间,在单条数据处理能力已经无法优化的情况下,发现真正的性能瓶颈不在于Flink自身,而是任务末端将处理后的数据写入到ElasticSearch这一阶段。
在执行流式处理过程中,上游一旦采集到数据,就会及时逐条处理,这也是流式处理的实时特征。根据我们的业务特征,平台在接收到上游采集的流式数据后,经过验证、清洗、转换与业务处理,会按照主题治理的要求,将处理后的数据写入到ElasticSearch。然而,这并非流任务处理的终点。数据在写入到ElasticSearch后,平台需要触发一个事件,应下游系统的要求,将上游传递的消息转换为出口消息。由于上游传递的消息不一定包含了出口消息的所有数据,在转换消息时,平台还需要查询ElasticSearch,获得包括最近更新的数据,作为组成出口消息的数据内容。
这里仍然存在时序性问题!在组成出口消息时需要查询ElasticSearch,这就要求最新的数据已经写入成功并能被检索到。由于ElasticSearch要支持全文本检索,写入数据时需要为其建立索引,也就是Lucene中的Segments,使得每次写操作的延迟相对于读操作而言要高一些。为了提升写入性能,ElasticSearch引入了in-memory buffer(内存缓冲区),提供了refresh(刷新)的三种方式:
即刻刷新
指定周期刷新,默认周期为1s,它也是ElasticSearch的默认值
当内存缓冲区满时刷新
只有即刻刷新,才能在一条数据写入到 Elasticsearch 后,能被马上搜索到。当上游采集的数据量非常多,且采用流式方式传入时,下游ElasticSearch的逐条写入与即刻刷新机制就成为了性能瓶颈。如果采用后两种刷新机制,又会导致索引未建立,无法即时搜索到最新数据,就会导致数据不一致。换言之,在我们的场景中,选择“即刻刷新”是必然的!要解决写入瓶颈的问题,最佳做法是放弃逐条写入,改为ElasticSearch支持的批量写入,如此即可减少不必要的连接,也能减少IO的次数。
虽说上游传递的流式数据需要实时进行处理,却并未要求它必须实时写入ElasticSearch,也未要求它必须实时推送给下游系统。当然,也不能延迟太长的时间。
为了权衡写入性能和数据正确性以及一致性,可以将实时写入改造为微批量的写入,如此,既能通过批量写入提升ElasticSearch的写入性能,又能保证数据必须成功写入到ElasticSearch后再推送消息,确保数据正确性与一致性。
团队成员想到了引入Flink的窗口,具体说来,是使用Flink时间窗口中的会话窗口与滚动窗口。
会话窗口的作用是在指定窗口周期内将相同key值的数据汇聚起来,我们为不同的key分配对应的会话窗口,而窗口好似一个桶,每个桶各自装各自key值的数据:
.keyBy(new KeyById()) |
如此这般,就能将1秒内相同key值的数据放到相同的会话窗口中,然后,通过reduce()算子对同一会话窗口中的数据进行合并,形成状态:
.reduce(new MergeWighSameId()) |
这一方式虽然实现了相同key数据的合并,但由于窗口的数量太过分散,导致数据汇聚的作用并不明显,没有达到批量写入提升性能的目的。
既然已经合并了相同key的数据,我们就可以减少窗口的数量,从而让不同key值的数据也能够汇聚到同一个窗口,形成数据的集合,交由下游进行批量写入。此时,选择的窗口为滚动窗口。
虽说窗口数量需要减少,但为了更好地利用资源,最好保证窗口的数量等于并行度。通过env.getParallelism()方法可以获得当前环境的并行度,在对数据的ID(它是数据的key)进行哈希值计算后,将并行度作为因子进行取模,就能将窗口数量压缩,天然实现数据的汇聚:
// 再执行了reduce后 |
对比改进前后的流式任务,下图是执行未加窗口的流式任务结果:
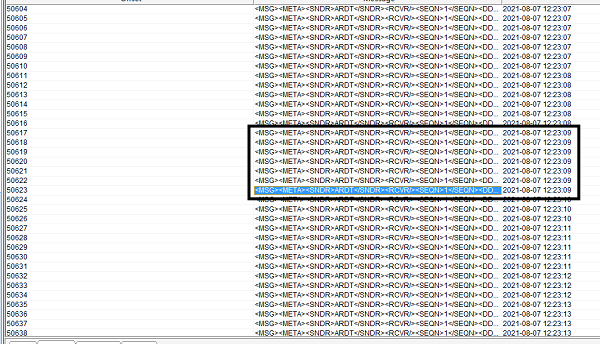
下图是执行加窗口后的流式任务结果:
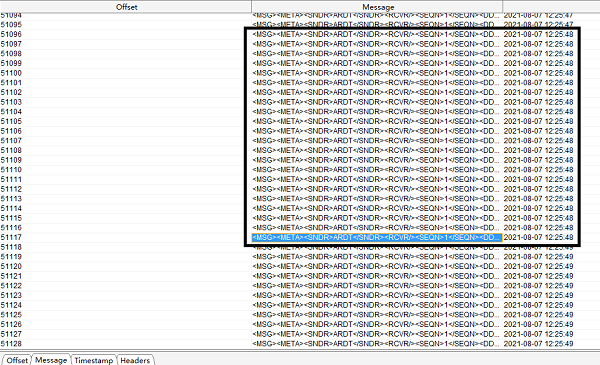
相同环境下,前者处理流式数据的频率大概为6条/秒左右,后者则达到了20条/秒左右,整体性能提升了3倍多,实现了不通过横向添加资源就完成了流式任务的性能优化,归根结底,在于我们发现了性能瓶颈,然后再对症下药,方可取得疗效。
说明:本文的技术方案与部分内容来自我的团队成员郑雄杰同学。