响应式编程在前端开发以及Android开发中有颇多运用,然而它的非阻塞异步编程模型以及对消息流的处理模式也在后端得到越来越多的应用。除了Netflix的OSS中大量使用了响应式编程之外,最近阿里也提出Dubbo 3.0版本将全面拥抱响应式编程。
我之前针对某些项目需求也给出了响应式编程的方案,较好地解决了并行编程与异步编程的问题。不过在深入了解响应式编程之后,我也给出了自己的一些实践总结。
响应式编程并非银弹
响应式编程并非银弹。事实上在软件领域,Brooks提出的“没有银弹”一说或许将永远生效。当我们在选择使用响应式编程时,一定要明确它的适用场景,主要包括:
- 处理由用户或其他系统发起的事件,如鼠标点击、键盘按键或者物联网设备等无时无刻都在发射信号的情况
- 处理磁盘或网络等高延迟的IO数据,且保证这些IO操作是异步的
- 业务的处理流程是流式的,且需要高响应的非阻塞操作
除此之外,我们当然也可以利用一些响应式编程框架如Rx,简化并发编程与数据流操作的实现。诸如RxJava就提供非常完整的工厂方法,可以将非响应式编程的Iterable、Array以及与响应式编程有一定相关性的Future、Callable转换为Observable或Flowable。
理解Source的本质
Akka Stream将流数据源定义为Source,RxJava则定义为Observable或Flowable。这些响应式编程框架都为Source提供了丰富的operator。其中除了组合流的操作之外,最基本的操作即为:filter、map、flatMap、reduce等。
粗略看来,这些操作皆为函数式的编程接口,从FP的角度看,我们甚至可以将Source视为一个monad。而站在Java编程的角度看,我们则很容易将Source视为等同于集合的数据结构。更何况,响应式编程实则脱胎于Observer模式与Iterator模式,其中Iterator模式就是针对集合的操作,只不过Observable或Flowable是push模型,而Iterator模式则为pull模型罢了。
然而这就是本质的区别,即Source是一个不断发射事件(data、error、complete)的源头,具有时间序列的特点,而Iterable则是一个静态的数据结构,在对它进行操作时,该数据结构中存储的数据就已经存在了。
合理设计Source的粒度
在演示Observable或Flowable的API时,我们往往喜欢采用Fluent Interface的方式连续地调用它的operator,形成一个整体的流处理过程。这并非总是合理的。当一个Source被多个operator串联起来的时候,会使得这个Source更加难以被重用。
例如,在加载网页时,默认发起对后端服务的调用并返回需要的用户信息,若建模为流A,其转换如下所示:
uri ----> user ----> | --> |
同时,有一个鼠标点击事件也会通过随机生成URL发起对后端服务的调用并返回需要的用户信息,倘若建模为流B,其转换如下所示:
click ----> uri ----> user ----> | --> |
显然,这两个流在从uri到user的流处理上出现了重复。如果我们创建的流A与流B并不包含uri到user的转换,就可以通过merge等合并操作将A与B合并,然后再共同重用从uri到user的转换。我们也无需担心创建细粒度流的成本,因为这些流的创建是lazy的,流虽然创建了,对流的操作却不会立即执行。
分离操作的逻辑
无论是哪个响应式框架,都为流(Source)提供了丰富的operator。这些operator多数都支持lambda表达式。在处理简单的业务逻辑时,这样的实现是没有问题的;然而一旦逻辑变得非常复杂,lambda表达式的表达能力就不够了。从编程实践看,lambda表达式本身就应该保持微小的粒度。这时,就应该将这些逻辑单独分离出来,放到单独的类与方法中。
例如,我们根据device的配置信息去调用远程服务获取设备信息,然后提取信息获得业务需要的指标,对指标进行转换,最后将转换的数据写入到数据库中。结合函数的转换本质,我们可以将这些操作拆分为多个连续的操作:
deviceConfig --> deviceInfo --> List<extractedInfo> --> transformedInfo --> write |
倘若这些转换的逻辑非常复杂,就可以将这些逻辑分别封装到DeviceFetcher、DeviceExtractor、DeviceTransformer与DeviceWriter这四个类中,于是代码可以写为:
Flowable.fromIterable(deviceConfigs) |
这一实践提倡将流的操作与每个操作的业务分离开,既能够保证流操作的简单与纯粹,又能保证操作业务的重用与可扩展。
API的设计
如果我们要设计符合响应式编程设计的API,则应该尽可能保证每个方法都是非阻塞的。要做到这一点,就应该保证每个方法返回的类型是Source或Publisher。例如针对要返回多个数据的流,可以返回Observable<T>或者Flowable<T>;如果确定只返回一个数据,则可以返回Single<T>;倘若不确定,则返回Maybe<T>。倘若该API方法仅仅是一个命令,无需返回结果,又需要保证方法是非阻塞的,则可以考虑返回Completable<T>。
从某种意义上说,返回Future<T>、CompletableFuture<T>或者CompletableStage<T>也可以认为是响应式的。这三个类型由于是JDK自身提供的,因此更纯粹。唯一不便的是这些接口没有提供类似Observable那样丰富的operator,但好在Observable与Flowable都提供了fromFuture()方法对其进行转换,因而这样的设计也是可取的。
Akka Stream的流拓扑图
Akka Stream对流处理的抽象被建模为图。这一设计思想使得流的处理变得更加直观,流的处理变成了“搭积木”游戏。可惜Java的DSL能力实在太弱,如果对比Scala与Java,你会发现GraphDSL对Graph的构造在表现上简直是天壤之别。
例如这是官方文档中Java版本对Graph的构造:
RunnableGraph.fromGraph(GraphDSL.create(builder -> { |
如下是官方文档中Scala版本对同一个Graph的构造:
RunnableGraph.fromGraph(GraphDSL.create() { implicit builder => |
我们也看到,倘若在GraphDSL中我们能够将构成Graph的“材料”对象事先创建好,而将build工作统一放在一起,可以在一定程度改进代码的表现力。
我们可以将Akka Stream的Graph(完整的Graph,称为ClosedShape,是可以运行的,又称之为RunnableShape)看做是流处理的”模具“,至于那些由Inlet与Outlet端口组成的基础Shape,则是设计这些模具的”基础材料“。
模具是静态的,基础材料与组合材料是可重用的单元,然后再组合可以重用的业务单元(以函数、类或者接口形式进行封装),这个模具就具有了业务处理能力。如果这个拓扑图过于复杂,我们还可以利用基础Shape组合形成一个个更粗粒度Partial Shap。这些Partial Shape不是封闭的,可以理解为更粗粒度的Source、Sink和Flow,它使得模具的组装变得更加简单。
材料、业务单元、模具之间的关系可以形象地用下图来表示:
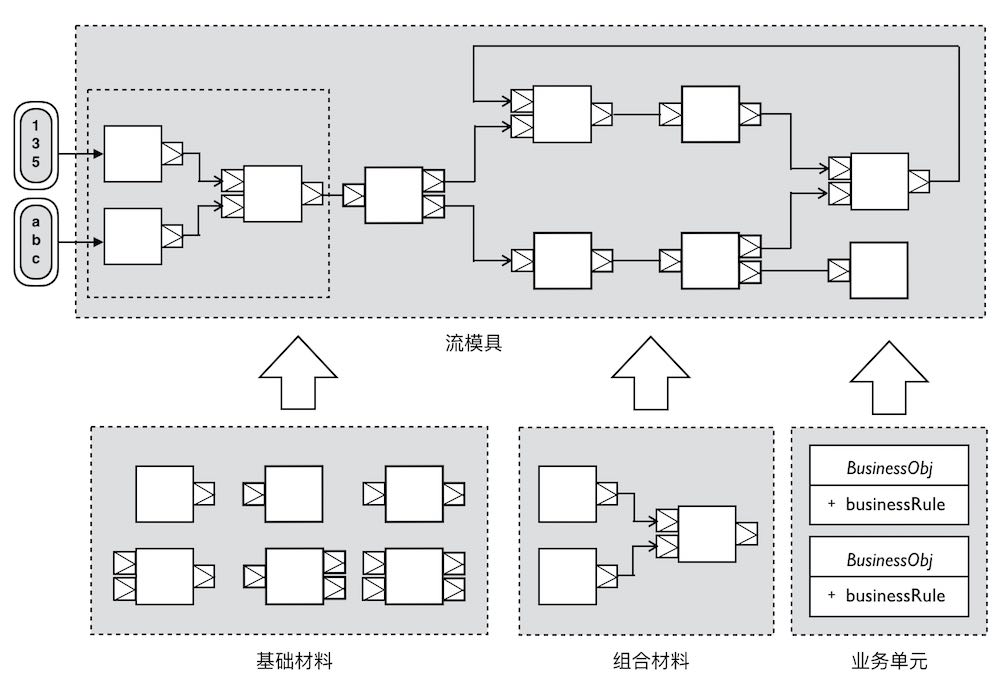
一旦流处理的模具打造完毕,打开数据流的”水龙头“,让数据源源不断地流入Graph中,流处理就可以”自动“运行。只要Source没有发出complete或error信号,它就将一直运行下去。Akka Stream之所以将Graph的运行器称之为materializer,大约也是源于这样的隐喻吧。
使用Akka Stream进行响应式流处理,我建议参考这样的思维。