
我们的产品需要对来自不同数据源的大数据进行采集,从数据源的多样化以及处理数据的低延迟与可伸缩角度考虑,需要选择适合项目的大数据流处理平台。我最初列出的候选平台包括Flume、Flink、Kafka Streaming以及Spark Streaming。然而对产品架构而言,这个技术选型的决策可谓举足轻重,倘若选择不当,可能会导致较大的修改成本,须得慎之又慎。
我除了在项目中曾经使用过Flume、Kafka以及Spark Streaming之外,对其余平台并不甚了解。即便是用过的这几个平台,也了解得比较肤浅。因此我查阅了这些平台的官方文档以及相关文章,偶然发现有Janakiram在2016年7月8日发表在The New Stack网站上的这篇文章All the Apache Streaming Projects: An Exploratory Guid,全(jian)面(dan)介绍了目前在Apache下主流的流处理项目,具有一定参考价值。因此摘译过来,以飧读者。
最近几年,数据的生成、消费、处理以及分析的速度惊人地增长,社交媒体、物联网、游戏等领域产生的数据都需要以接近实时的速度处理和分析数据。这直接催生了流数据的处理范式。从Kafka到Beam,即使是在Apache基金下,已有多个流处理项目运用于不同的业务场景。
Apache Flume
Apache Flume或许是Apache众多项目中用于流数据处理的最古老项目了,其设计目的是针对诸如日志之类的数据进行采集、聚合和迁移。Flume基于agent-driven architecture,客户端生成的事件会以流的形式直接写入到Hive、HBase或者其他数据存储。
Flume由Source、Channel和Sink组成。Source可以是系统日志、Twitter流或者Avro。Channel定义了如何将流传输到目的地。Channel的可用选项包括Memory、JDBC、Kafka、文件等。Sink则决定了流传输的目的地。Flume支持如HDFS、Hive、HBase、ElasticSearch、Kafka等Sink。
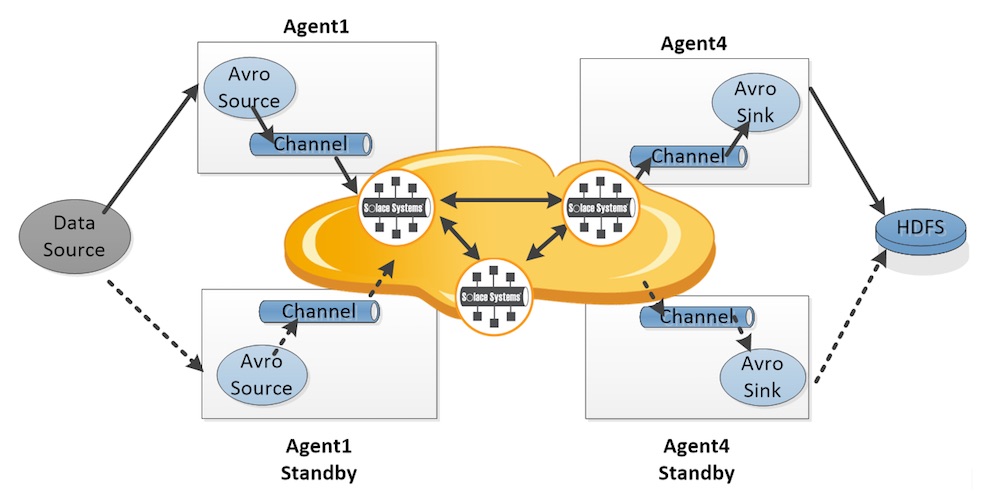
使用Flume的最常见场景是从多个源头采集流日志汇总并持久化到数据中心,以便于进一步地处理与分析。
典型用例:对来自于多个可以运行在JVM上的Source的日志进行流处理。
Apache Spark
Apache Spark为开发者提供了基于RDD的API,RDD被称为弹性分布式数据集,是一个只读的数据集,可以分布于多个机器集群,具有容错性。Spark的诞生本身是为了解决MapReduce的性能限制,它以内存模型对数据进行处理和分析,从而提高了处理的性能。
Spark使用Scala进行开发,但它也支持Java、Python和R语言,支持的数据源包括HDFS、Cassandra、HBase与Amazon S3等。
Spark Streaming是Spark其中的一个组件,用于高容错的流处理应用。由于它运行在Spark之上,因而允许开发人员重用批处理的相同代码,针对历史数据进行join流操作,或者针对流状态进行即刻查询。Spark Streaming采用了micro-batching模式,即本质上还是批处理,但处理的单元可以非常微小。

Spark还可以运行在已有的Hadoop与Mesos集群上,并为探索数据提供了声明式的shell编写能力。
Apache Spark可以与Apache Kafka配套,提供强大的流处理环境。
典型用例:实时处理社交媒体的feed,以进行情感分析。
Apache Storm
Apache Storm最初由Twitter旗下的BackType公司员工Nathan Marz使用Clojure开发。在获得授权后,Twitter将Storm开源。它一诞生就几乎成为分布式的实时数据处理平台的标准。
Storm常常被认为是Hadoop下的实时处理平台,官方文档则宣称:它能够像Hadoop进行批处理那样对数据进行实时处理。
Apache Storm的主要设计目的是为了追求系统的可伸缩性与高容错性。它能够保证每条tuple数据至少能够被处理一次。虽然系统是由Clojure编写,但应用的编写却可以支持各种语言,只要这种语言能够读写标准的输入和输出流。
Storm连接的输入流称之为“spouts”和“bolts”,对应处理和输出模块。spouts和bolts的集合组成了有向无环图(DAG),在Storm中称之为拓扑(topology)。基于预先定义的配置,拓扑可以运行在集群上,根据scheduler对工作进行跨节点的分发。
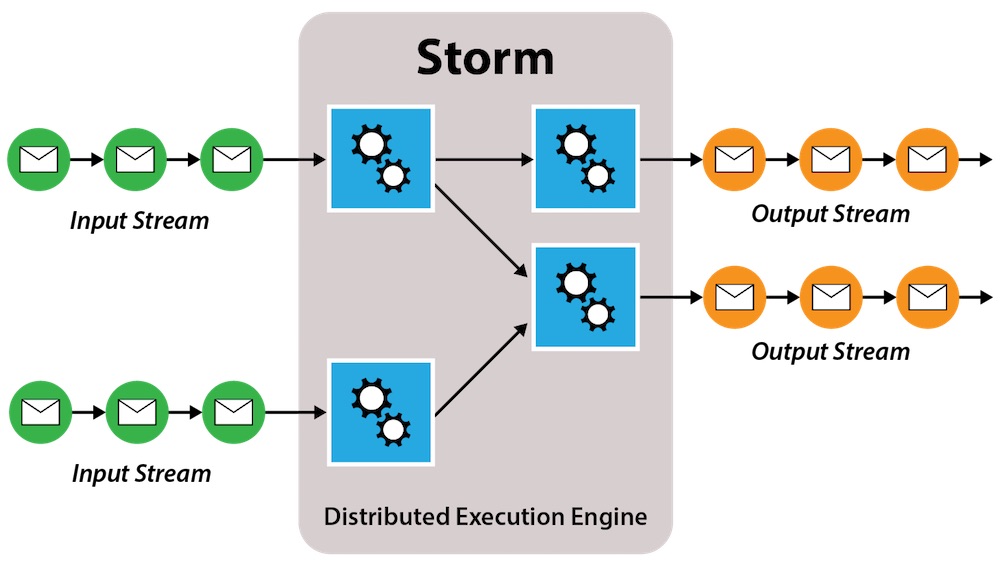
Storm的拓扑常常与Hadoop MapReduce的Job对比。但是不同于Hadoop Job,拓扑可以持续不断地执行,直到它被终止。在拓扑中,Spouts获取数据并通过一系列的bolts进行传递。每个bolt会负责对数据的转换与处理。一些bolt还可以将数据写入到持久化的数据库或文件中,也可以调用第三方API对数据进行转换。
基于适配器的概念,Storm可以与HDFS文件系统协作,并作为Hadoop Job参与。
通常会将Storm与Apache Kafka和Apache Spark混合使用。Storm提供了可靠的、可伸缩的高容错分布式计算框架。
典型用例:实时转换和处理社交媒体/物联网传感器流。
Apache NiFi
和其他流处理方案相比,Apache NiFi相对较新,在2015年7月才成为Apache的顶级项目。它基于企业集成模式(Enterprise Integration Patterns, EIP),将数据流分为多个阶段和转换,最后到达目的地。
Apache NiFi提供了直观的图形界面,使得用户可以非常方便地设计数据流与转换。业务分析师和决策者可以使用这个工具来定义数据流。它还支持各种输入源包括静态和流的数据集。数据源可以是文件系统、社交媒体流、Kafka、FTP、HTTP、JMS,流向的目的地则包括ElasticSearch、Amazon S3、AWS Lambda、Splunk、Solr、SQL和NoSQL数据库。
在物联网领域,Apache NiFi有可能成为处理传感器数据的首选编排引擎。它提供了具有大数据处理能力的Node-Red简化,所谓Node-Red是面向物联网的基于流的编程模型。NiFi内建支持Kafka、JMS以及其他通道。
Apache NiFi的一个经典场景是用于对Hot Path与Cold Path的创建。数据集通常可以流经高速度的处理引擎,如Apache Kafka、Amazon Kinesis和Azure Event Hubs。Apache NiFi可以将相同的数据集分为两个独立的路径,一个用于近实时的处理(hot path),一个用于批处理(code path)。
典型用例:一个交互式的规则引擎,用于定义物联网传感器数据流。
Apache Apex
Apache Apex由一家硅谷公司DataTorrent捐赠给Apache基金会,之前是实时流处理的商业产品。这是一个年轻的项目,刚刚(相对这篇文章的写作日期2016年)从孵化版本升级为顶级项目。它的定位就是在实时流处理上取代Storm与Spark,号称处理速度是Spark的10到100倍。
相较于Spark,Apex提供了一些企业特性,如事件处理、事件传递的顺序保证与高容错性。与Spark需要熟练的Scala技能不同,Apex更适合Java开发者。它可以运行在已有的Hadoop生态环境中,使用YARN用于扩容,使用HDFS用于容错。
Apache Apex的目标是打造企业级别的开源数据处理引擎,可以处理批量数据和流数据。使用时可以根据具体的业务场景选择所谓unbounded data的实时流处理或者传统文件形式的bounded data处理,且这两种处理方式在Apex下是统一的。
Apache Apex的架构可以读/写消息总线、文件系统、数据库或其他类型的源。只要这些源的客户端代码可以运行在JVM上,就可以无缝集成。
Apex使用了一个操作子(operators)库,称之为Malhar,它为读写消息总线、文件系统和数据库提供了预先构建的操作子。这些操作子使得开发者能够快速构建业务逻辑,用于处理各种数据源。Apex的整体目标就是为了简化企业应用中大数据项目的复杂度。
典型用例:运行在高容错基础设施之上的应用,需要以实时和批模式处理异构数据。
Apache Kafka Streams
Kafka Streams仅仅是构建在Apache Kafka之上的一个库,由Confluent贡献,这是一家由LinkedIn参与Kafka项目的早期开发者创建的初创公司。
在过去的几年内,Apache Kafka以实时与大规模消息系统著称,并变得越来越普及,快速成为了大数据平台的核心基础构件。它被广泛应用于各行各业的上千家公司,包括Netflix、Cisco、PayPal与Twitter。公有云的提供商在其提供的大数据分析平台之上,都将Kafka作为一个托管的服务。
Kafka Streams是一个用于构建流应用的库,特别用于处理将Kafka topics转换为输出的Kafka topics。它的设计初衷并不是为了大量分析任务,而是用于微服务架构,进行高效而精简的流处理。这意味着Kafka Streams库用于应用程序的核心业务逻辑集成,而非用于大量的分析Job。
Kafka Streams将用户从繁杂的安装、配置以及管理复杂Spark集群中解放出来。它简化了流处理,使其作为一个独立运行的应用编程模型,用于响应异步服务。开发者可以引入Kafka Streams满足其流处理的功能,却无需流处理的集群(因为Kafka已经提供)。除了Apache Kafka,在架构上并没有其他外部依赖。Kafka Streams提供的处理模型可以完全与Kafka的核心抽象整合。
在讨论Kafka Streams时,往往会谈及Kafka Connect。后者用于可靠地将Kafka与外部系统如数据库、Key-Value存储、检索索引与文件系统连接。
Kafka Streams最棒的一点是它可以作为容器打包到Docker中。DevOps团队也可以使用Ansible、Puppet、Chef、Salt甚或shell脚本部署和管理它的应用。一旦被打包为容器,它就可以与一些编排引擎集成,如Docker Swarm、Kubernetes、DC/OS、Yarn等。
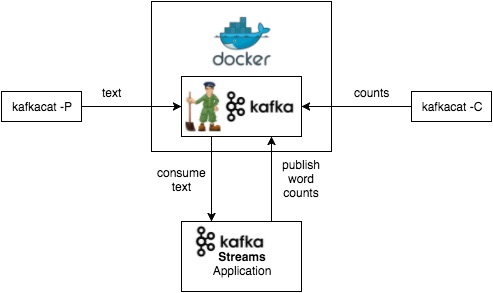
典型用例:需要进行流处理,但又不希望依赖复杂集群的微服务与独立部署的应用。
Apache Samza
Apache Samza由LinkedIn开发,目的是为了避免Hadoop批处理引入的长时运转时间(large turn-around times)问题。它构建于Kafka之上。Samza提供了持续数据处理的轻量级框架。
Kafka与Samza的搭配就好比HDFS与MapReduce的搭配。当数据到达时,Samza可以持续计算结果,并能达到亚秒级的响应时间。
在从流获得输入后,Samza会执行Job。可以通过编码实现Job对一系列输入流的消费与处理。编写Job可以使用Java、Scala或其他JVM下的编程语言。为了支持可伸缩性,Job也可以被分解为多个小的并行执行单元,称之为Task。每个Task可以消费其中一个分区传递的流数据。一个任务会顺序地处理来自其输入分区的数据,并保证消息的顺序。分区之间并没有定义顺序,因此允许每个任务独立对其进行操作。
Samza会在一个或多个容器(container)中将多个任务组合起来执行。在Samza中,容器是单个线程,负责管理任务的生命周期。
Samza与其他流处理技术的不同之处在于它的有状态流处理能力。Samza任务具有专门的key/value存储并作为任务放在相同的机器中。这一架构使得它比其他流处理平台具有更好的读/写性能。
当使用Kafka进行数据采集时,架构上Samza会是一个自然的选择。
Apache Samza与Kafka Streams解决的问题类似,在将来可能会被合并为一个项目。
典型用例:使用Kafka进行数据采集的更优化流处理框架。
Apache Flink
Apache Flink在2014年12月成为Apache顶级项目。它的概念以及使用场景看起来与Spark相似,其目的在于提供运行批数据、流、交互式、图处理以及机器学习应用的一体化平台,但是二者在实现上存在差别。
Spark Streaming是以处理迷你批数据的方式实现准实时处理能力。Apache Flink则提供了实时处理能力,这源于其细粒度的事件级别处理架构(fine-grained event level processing architecture)。
Flink提供了消息处理恰好一次(exactly-once)的保证,这就使得开发者不用再处理冗余消息。它提供了高吞吐量的引擎,在事件发送到分布式网络之前提供了buffer功能。同时,它还具有灵活的windowing scheme,以支持强大的流编程模型。
Flink提供DataStream API用于流数据的分析,DataSet API用于批数据的分析,二者皆建立在底层的流处理引擎之上。
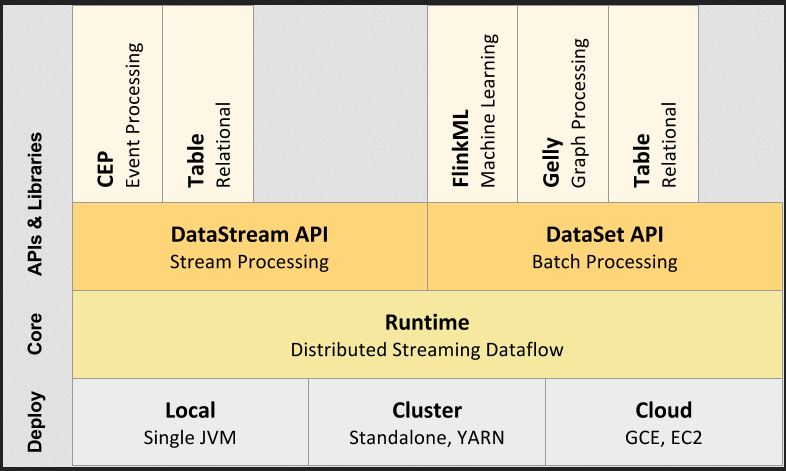
Apache Flink支持Java或Scala编程。它没有提供数据存储系统。输入数据可以来自于分布式存储系统如HDFS或HBase。针对流处理场景,Flink可以消费来自诸如Kafka之类的消息队列的数据。
典型用例:实时处理信用卡交易。
Apache Beam
Apache Beam同样支持批处理和流处理模型,它基于一套定义和执行并行数据处理管道的统一模型。Beam提供了一套特定语言的SDK,用于构建管道和执行管道的特定运行时的运行器(Runner)。
Beam演化于Google的几个内部项目,包括MapReduce、FlumeJava和Millwheel。在Beam中,管道运行器(Pipeline Runners)会将数据处理管道翻译为与多个分布式处理后端兼容的API。管道是工作在数据集上的处理单元的链条。取决于管道执行的位置,每个Beam程序在后端都有一个运行器。当前的平台支持包括Google Cloud Dataflow、Apache Flink与Apache Spark的运行器。Storm和MapReduce的运行器孩还在开发中(译注:指撰写该文章的2016年。我通过查看Beam的官方网站,看到目前支持的runner还包含了Apex和Gearpump,似乎对Storm与MapReduce的支持仍然在研发中)。
Dataflow试图在代码与执行运行时之间建立一个抽象层。当代码在Dataflow SDK中被实现后,就可以运行在多个后端,如Flink和Spark。Beam支持Java和Python,其目的是将多语言、框架和SDK融合在一个统一的编程模型中。
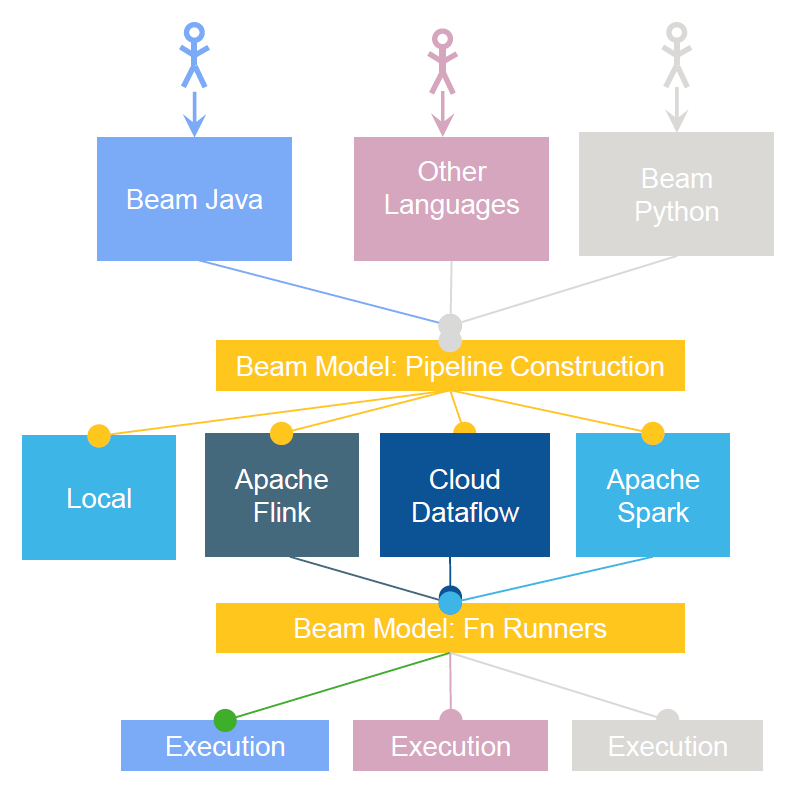
典型用例:依赖与多个框架如Spark和Flink的应用程序。
Apache Ignite
Apache Ignite是搭建于分布式内存运算平台之上的内存层,它能够对实时处理大数据集进行性能优化。内存模型的架构比传统的基于磁盘或闪存的技术要快。
Apache Ignite于2015年9月从孵化版升级为Apache顶级项目。
虽然Spark与Ignite都是基于分布式的内存处理架构,但二者却存在差别。Spark主要用于交互式分析(interactive analytics)以及机器学习,而Ignite则提供编程式的实时分析、机器对机器的通信以及高性能的事务处理。
对于交易处理系统例如股票交易、反欺诈、实时建模与分析而言,Ignite可能会成为首选。它既支持通过添加硬件的方式进行水平伸缩,也支持在工作站以及专用服务器上的垂直伸缩。
Ignite的流处理特性能够支持持续不断地没有终止的数据流,并具有可伸缩和高容错的能力。
典型用例:高度依赖于编程形式的实时分析应用,机器对机器的通信以及高性能的事务处理。
这篇文章并没有为大数据流处理技术选型提供充分的证据支持,对这些项目的介绍仅仅是泛泛而谈,但它为选型提供了相对完整的列表,让我们知道了到底有多少主流的且较为成熟的流处理平台,因而仍然具有一定的参考价值。