选择太多,是一件好事情,不过也容易乱花渐欲迷人眼。倘若每个平台(技术)都去动手操练一下,似乎又太耗时间。通过阅读一些文档,可以帮我们快速做一次筛选。在将选择范围进一步缩小后,接下来就可以结合自己的应用场景去深入Spike,做深度的甄别,这是我做技术选型的一个方法。
技术没有最好,只有最适用。在做技术选型时,需要选择适合需求、适合项目类型、适合团队的技术。这是实用主义的判断,而非理想主义的追捧。若是在实用的技术选型中,再能点燃一些些技术上的情怀,那就perfect了!
属性矩阵(Attributes Matrix)
我在《Apache下流处理项目巡览》一文中翻译了Janakiram的这篇文章,介绍了Apache基金会下最主流的流处理项目。巧的是,我在InfoQ上又发现了Ian Hellstrom的文章,他用一张图给出了非常棒的总结。
为了更好地阅读,我将这张图的内容转成如下的矩阵表。由于Ian的文章是2016年撰写的,我对其内容做了适度更新。
表一: 流平台的质量属性
流平台 | 当前版本 | 主要推动者 | Event Size | 消息传递保证 | 状态管理
— | — | — | — | — | — | —
Flume | 1.8.0 | Apple, Cloudera | single | at least once | 事务型更新
NiFi | 1.5.0 | Hortonworks | single | at least once | 本地及分布式快照
Gearpump | 0.8.4 | single | Intel, Lightbend | exactly once,若不需要支持容错,则为at least once | checkpoints
Apex | Apex Core 3.6.0, Apex Malhar 3.8.0 | Data Torrent | single | exactly once | checkpoints
Kafka Streams | 1.0 | Confluent | single | at least once | 本地及分布式快照
Spark Streaming | 2.2.1 | AMPLab, Databricks | micro-batch | exactly once,若不需要支持容错,则为at least once | checkpoints
Storm | 1.1.1 | Backtype, Twitter | single | at least once | record acknowledgements
Samza | 0.14.0 | Linkedin | single | at least once | 本地快照,分布式快照则支持容错
Flink | 1.4.0 | dataArtisans | single | exactly once | 分布式快照
Ignite Streaming | 2.3.0 | GridGain | single | at least once | checkpoints
Beam | 2.2.0 | Google | single | exactly once | 事务型更新
表一(续):流平台的质量属性
流平台 | 容错 | 处理顺序 | 事件的优先级 | Windowing | Back-pressure(背压)
— | — | — | — | — | — | —
Flume | yes(只针对file channel) | no | no | no | no
NiFi | yes | no | yes | no | yes
Gearpump | yes | yes | programmable | time-based | yes
Apex | yes | no | programmable | time-based | yes
Kafka Streams | yes | yes | programmable | time-based | N/A
Spark Streaming | yes | no | programmable | time-based | yes
Storm | yes | yes | programmable | time-based, count-based | yes
Samza | yes | yes(单分区情况则不支持) | programmable | time-based, count-based | yes
Flink | yes | yes | programmable | time-based, count-based | yes
Ignite Streaming | yes | yes | programmable | time-based, count-based | yes
Beam | yes | yes | programmable | time-based | yes
表一(再续):流平台的质量属性
流平台 | 数据抽象 | 数据流 | 延迟 | 资源管理 | Auto-scaling
— | — | — | — | — | — | —
Flume | Event | agent | low | native | no
NiFi | FlowFile | flow | configurable | native | no
Gearpump | Message | streaming application | very low | YARN | no
Apex | Tuple | streaming application | very low | YARN | yes
Kafka Streams | KafkaStream | process topology | very low | YARN, Mesos, Chef, Puppet, Salt, Kubernetes等 | yes
Spark Streaming | DStream | application | medium | YARN, Mesos | yes
Storm | Tuple | topology | very low | YARN, Mesos | no
Samza | Message | job | low | YARN | no
Flink | DataStream | streaming dataflow | low(configurable) | YARN | no
Ignite Streaming | IgniteDataStreamer | job | very low | YARN, Mesos | no
Beam | PCollection | pipeline | low | integrated | yes
表一(终):流平台的质量属性
流平台 | 热修改 | API | 主要开发语言 | API语言
— | — | — | — | — | — | —
Flume | no | declarative | Java | text files, Java
NiFi | yes | compositional | Java | REST(GUI)
Gearpump | yes | declarative | Scala | Scala, Java
Apex | yes | declarative | Java | Java
Kafka Streams | yes | declarative | Java | Java
Spark Streaming | no | declarative | Scala | Scala, Java, Python
Storm | yes | compositional | Clojure | Scala, Java, Clojure, Python, Ruby
Samza | no | compositional | Scala | Java
Flink | no | declarative | Java | Java, Scala, Python
Ignite Streaming | no | declarative | Java | Java, .NET, C++
Beam | no | declarative | Java | Java
数据流模型
在进行流数据处理时,必然需要消费上游的数据源,并在处理数据后输出到指定的存储,以待之后的数据分析。站在流数据的角度,无论其对数据的抽象是什么,都可以视为是对消息的生产与消费。这个过程是一个数据流(data flow),那么负责参与其中的设计元素就可以称之为是“数据流模型(Data flow model)”。
不同流处理平台的数据流模型有自己的抽象定义,也提供了内建的支持。我针对Flume、Flink、Storm、Apex以及NiFi的数据流模型作了一个简单的总结。
Flume
Flume的数据流模型是在Agent中由Source、Channel与Sink组成。
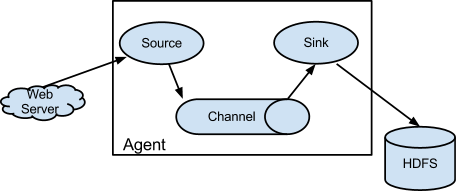
内建的Source支持:
- Avro
- Thrift
- JMS
- Taildir
- Exec
- Spooling Directory
- Kafka
- NetCat
- Sequence Generator
- Syslog
- HTTP
内建的Sink支持:
- HDFS
- Hive
- Logger
- Avro
- Thrift
- IRC
- File Roll
- HBase
- Solr
- Elasticsearch
- Kite Dataset
- Kafka
- HTTP
Flume还支持自定义Source、Sink与Channel。
Flink
Flink将数据流模型抽象为Connector。Connector将Source与Sink连接起来,一些特殊的connector则只有Source或Sink。Flink定义的connector包括:
- Kafka(支持Source/Sink)
- Elasticsearch(仅为Sink)
- HDFS(仅为Sink)
- RabbitMQ(支持Source/Sink)
- Amazon Kinesis Streams(支持Source/Sink)
- Twitter(仅为Source)
- NiFi(支持Sink/Source)
- Cassandra(仅为Sink)
- Redis、Flume和ActiveMQ(仅为Sink)
Flink也支持用户自定义Connector。
Storm
Storm对数据流模型的抽象则形象地定义为Spout和Bolt。为了支持其他数据源的读取,并将数据存储到指定位置,Storm提供了与诸多外部系统的集成,并针对这些外部系统去定义对应的Spout与Bolt。
Storm集成的外部系统包括:
- Kafka:通过
BrokerHosts的ZKHosts支持Spout - HBase:提供
HBaseBolt - HDFS:提供
HdfsBolt - Hive:提供
HiveBolt - Solr:提供
SolrUpdateBolt与对应的Mapper - Canssandra:提供
CassandraWriterBolt - JDBC:提供
JdbcInsertBolt与JdbcLookupBolt等 - JMS:提供JMS Spout与JMS Bolt
- Redis:提供
RedisLookupBolt、RedisStoreBolt与RedisFilterBolt等 - Event Hubs:提供了Event Hubs Spout
- Elasticsearch:提供
EsIndexBolt、EsPercolateBolt与EsLookupBolt等 - MQTT:MQTT主要用于物联网应用的轻量级发布/订阅协议,提供了对应的Spout
- MongoDB:提供了
MongoInsertBolt、MongoUpdateBolt - OpenTSDB
- Kinesis
- Druid
- Kestrel
Storm和Storm Trident都支持用户自定义Spout和Bolt。
Apex
Apex将数据流模型称之为Operators,并将其分离出来,放到单独的Apex Malhar中。对于Source,它将其称之为Input Operators,对于Sink,则称为Output Operators,而Comput Operators则负责对流数据的处理。
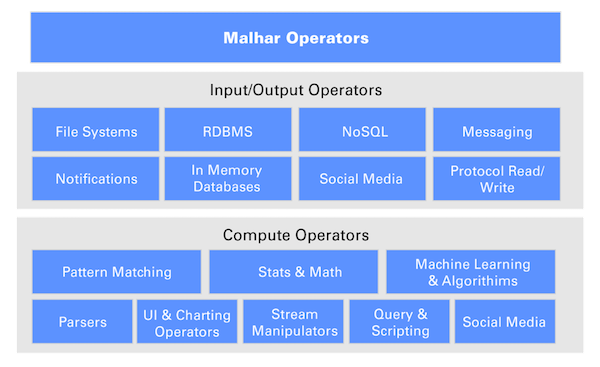
Apex Malhar支持的Input/Output Operators包括:
- 文件系统:支持存储到HDFS、S3,也可以存储到NFS和本地文件系统
- 关系型数据库:支持Oracle、MySQL、Sqlite等
- NoSQL数据库:支持HBase、Cassandra、Accumulo、Aerospike、MongoDB和CouchDB
- 消息系统:支持对Kafka、JMS、ZeroMQ和RabbitMQ消息的读写
- 通知系统:支持通过SMTP发送通知
- 内存数据库和缓存:支持Memcached和Redis
- 社交媒体:支持Twitter
- 协议:支持HTTP、RSS、Socket、WebSocket、FTP和MQTT
毫无疑问,Apex也支持用户自定义Operator。除了可以用Java编写之外,还可以使用JavaScript、Python、R和Ruby。
NiFi
NiFi对流模型的主要抽象为Processor,并且提供了非常丰富的数据源与数据目标的支持。
常用的数据采集方法包括:
- GetFile
- GetFtp
- GetSFtp
- GetJMSQueue
- GetJMSTopic
- GetHTTP
- ListenHTTP
- ListenUDP
- GetHDFS
- ListHDFS / FetchHDFS
- FetchS3Objet
- GetKafka
- GetMongo
- GetTwitter
发送数据的方法包括:
- PutEmail
- PutFile
- PutFTP
- putSFTP
- PutJMS
- PutSQL
- PutKafka
- PutMongo
Nifi也支持用户自定义Processor,例如通过继承NiFi定义的AbstractProcessor类。自定义的Processor可以和内建的Processor一样添加到NiFi定义Flow的GUI上,并对其进行配置。