很难说FP和OO孰优孰劣,应该依场景合理选择使用。倘若从这个角度出发,Scala就体现出好处了,毕竟它同时支持了OO和FP两种设计范式。
从设计角度看,我认为OO更强调对象的自治 ,即每个对象承担自己应该履行的职责。倘若在编码实现时能遵循“自治”原则,就不容易设计出贫血对象出来。FP则更强调函数的分治 ,即努力保证函数的纯粹性和原子性,对一个大问题进行充分地分解,分别治理,然后再利用函数的组合性完成职责的履行,即所谓“通过增量组合建立抽象”。
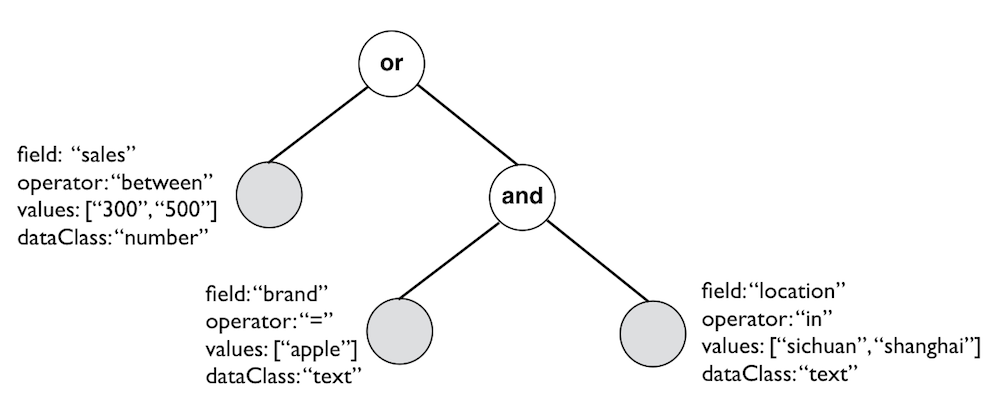
需求 我最近正在编写的一个需求场景,正好完美地展现了这两种不同范式的设计威力。我要实现的是一个条件表达式树的验证和解析,这棵树的节点分为两种类型:
Condition Group
Condition
Condition Group作为根节点,可以递归嵌套Condition Group和Condition,如下图所示:
对条件表达式树的验证主要是避免出现非法节点,例如不支持的操作符,不符合要求的条件值,不合理的递归嵌套,空节点等。若验证不通过则需要提供错误信息,并返回给前端400的BadRequest。解析时,必须保证节点是合规的,解析后的结果为满足SQL语法中where条件子句的字符串。
验证 针对表达式数的合规性验证,我选择了FP的实现方式。为何做出这样的选择?试剖析整个验证行为,可以分解为如下的验证逻辑:
对表达式树的验证
对当前Condition节点的验证
对当前Condition Group节点的验证
可以看到,分解出来的处于同一层次的验证逻辑,彼此之间是完全正交的,获得的结果互相不受影响。同时,这些“原子”的验证逻辑又可以组合起来,形成更高粒度的正交的验证,例如对Condition和Condition Group的验证,彼此独立,组合起来却又可以形成对整个表达式树的验证。
考虑函数的side effect,应尽量做到无副作用,这更选择选择FP的方式,且Scala自身提供了Try[T]类型,可以避免在函数中抛出具有副作用的异常。Try[T]是一个Monad,可以支持for comprehension对函数进行组合。
由于验证逻辑彼此正交,对函数的实现就变得非常纯粹而简单,不用考虑太多外在的因素。只要设计好函数的接口,函数可以专心做自己的事情。
对Condition当前节点的验证 对Condition的验证相对简单,只需要分别针对操作符和条件值进行验证即可。如下是代码实现:
trait ConditionValidator def validateCondition Condition ): Try [Boolean ] = { for { _ <- validateOperator(condition) result <- validateValues(condition) } yield result } def validateOperator Condition ): Try [Boolean ] = { List ("between" , "in" , "<" , ">" , "=" , "<=" , ">=" , "<>" ).contains(condition.operator.toLowerCase) match { case true => Success (true ) case false => Failure (new Throwable (s"can't support operator ${condition.operator} " )) } } def validateValues Condition ): Try [Boolean ] = { val error = new Throwable (s"invalid values for condition ${condition} " ) if (condition.values.isEmpty) return Failure (error) if (condition.operator.isBetween && condition.values.size != 2 ) return Failure (error) if (condition.operator.isCommon && condition.values.size != 1 ) return Failure (error) Success (true ) } implicit class StringOperator (operator: String ) def isBetween Boolean = operator.toLowerCase == "between" def isIn Boolean = operator.toLowerCase == "in" def isCommon Boolean = List ("<" , ">" , "=" , "<=" , ">=" , "<>" ).contains(operator.toLowerCase) } }
对ConditionGroup当前节点的验证 这里对ConditionGroup的验证仅仅针对当前节点,不用去考虑ConditionGroup的嵌套,那是对表达式树的验证,属于另一个层次。把这一职责的边界明确界定,代码实现就变得非常的简单:
trait ConditionGroupValidator def validateConditionGroup ConditionGroup ): Try [Boolean ] = { for { _ <- validateLogicOperator(group) result <- validateConditionSize(group) } yield result } def validateConditionSize ConditionGroup ): Try [Boolean ] = { val error = new Throwable (s"invalid condition group for ${group} " ) group.logicOperator.toLowerCase match { case "not" => if (group.conditions.size == 1 ) Success (true ) else Failure (error) case _ => if (group.conditions.size >= 2 ) Success (true ) else Failure (error) } } def validateLogicOperator ConditionGroup ): Try [Boolean ] = { List ("and" , "or" , "not" ).contains(group.logicOperator.toLowerCase()) match { case true => Success (true ) case false => Failure (new Throwable (s"invalid logic operator ${group.logicOperator} for ConditionGroup" )) } } }
对表达式树的验证 对表达式树的验证相对复杂,因为牵涉到递归,尤其是从性能考虑,需要使用尾递归(tail recursion)。关于尾递归的知识,在我之前的博客《艾舍尔的画手与尾递归 》中已有详细介绍,这里不再赘述。阅读下面的代码实现时,注意尾递归方法recurseValidate()的第二个参数,其实就是关键的accumulator。
trait CriteriaValidator extends ConditionValidator with ConditionGroupValidator def validate ConditionGroup ): Try [Boolean ] = { @tailrec def recurseValidate List [ConditionExpression ], result: Try [Boolean ]): Try [Boolean ] = { val ex = new Throwable (s"invalid condition group ${group} " ) expr match { case Nil => Failure (ex) case head::Nil => result.flatMap(_ => validateExpression(head)) case head::tail => recurseValidate(tail, validateExpression(head)) } } validateConditionGroup(group).flatMap(_ => recurseValidate(group.conditions, Success (true ))) } def validateExpression ConditionExpression ): Try [Boolean ] = expr match { case expr: ConditionGroup => validateConditionGroup(expr) case expr: Condition => validateCondition(expr) } }
注意,在函数validate()中,实际上是验证ConditionGroup当前节点的函数validateConditionGroup()与尾递归方法recurseValidate()的组合。至于validateExpression()函数的引入,不过是为了避免不必要的类型判断和强制类型转换罢了。
解析 我最初也曾尝试依旧采用FP方式实现解析功能。思索良久,发现要实现起来困难重重。最主要的障碍在于:每个解析行为返回的结果都会影响到别的节点,进而影响整个表达式。例如,为了保证解析后where子句的语法合规,需要考虑为每个节点解析的结果添加小括号。当对整个表达式树进行递归解析时,每次返回的结果无法直接作为accumulator的值。如果在当前递归层添加了小括号,由于该层次下的子节点还未得到解析,就会导致小括号范围有误;如果不添加小括号,就无法界定各个层次逻辑子句的优先级,导致筛选结果不符合预期。换言之,其中的关键在于每个解析操作并非正交的 ,因此无法对函数进行“分治”的拆解。
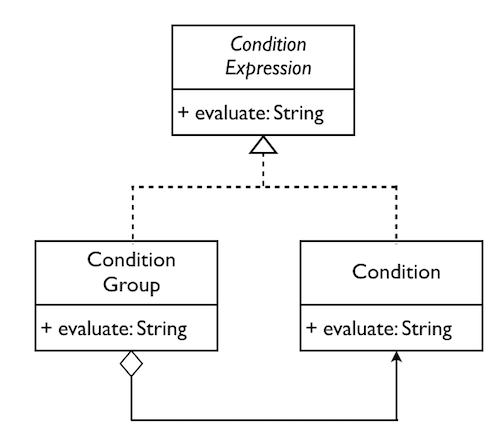
倘若站在OO的角度去思考,则对条件表达式的解析,实际就是对各个节点的解析。由于解析行为需要的数据是各个节点对象已经具备的,遵循信息专家模式 ,就应该让节点对象自己来履行职责,这就是所谓的“对象的自治” 。而从抽象层面进行分析,虽然各个节点拥有的数据不同,解析行为的实现也不尽相同,却都是在完成对自身的解析。于是,我们通过ConditionExpression完成对不同节点类型的抽象。此时,Condition Group是表达式树的枝节点,而Condition则是表达式树的叶子节点。如下图所示,不恰好是Composite模式的体现么?
我们首先需要定义ConditionExpression抽象。这里之所以定义为抽象类,而非trait,是为了支持Json解析的多态,与本文无关,这里不再解释。若希望了解,请阅读我的另一篇博客《在Scala项目中使用Spring Cloud 》:
abstract class ConditionExpression def evaluate String }
作为枝节点的ConditionGroup,不仅要解析自身,还要负责解析嵌套的子节点。但是,父节点不用考虑解析子节点内部的实现,它仅仅是在合适的地方发起对子节点的调用就可以了。这才是真正的“自治”,也就是每个对象在理智上都保持对“权力的克制”,仅负责履行属于自己的职责,绝不越权。
case class ConditionGroup (logicOperator: String , conditions: List [ConditionExpression ] ) extends ConditionExpression def evaluate String = { logicOperator.toLowerCase match { case "not" => s"(NOT ${conditions.head.evaluate} )" case _ => { val expr = conditions.map(_.evaluate).reduce((l, r) => s"${l} ${logicOperator.toUpperCase} ${r} " ) s"($expr )" } } } } case class Condition (fieldName: String , operator: String , values: List [String ], dataType: String ) extends ConditionExpression def evaluate String = { def handleValue String , dataType: String ): String = { dataType.toLowerCase match { case "text" => s"'${value} '" case "number" => value case _ => value } } val correctValues = values.map(v => handleValue(v, dataType)) val expr = operator.toLowerCase() match { case "between" => s"BETWEEN ${correctValues.head} AND ${correctValues.last} " case "in" => { val range = correctValues.map(x => s"$x " ).mkString("," ) s"IN (${range} )" } case _ => s"${operator.toUpperCase} ${correctValues.head} " } s"(${fieldName} ${expr} )" } }
组合验证与解析 若采用自顶向下的设计方法来看待整个功能,则表达式树的验证与解析属于两个不同的职责,遵循“单一职责原则”,我们应该将其分离。在进行验证时,无需考虑解析的逻辑;在开始解析表达式树时,也无需负担验证合法性的包袱。分则简易,合则纠缠不清。只有进行了合理地“分治”后然后再组合,景色就大不相同了:
trait CriteriaParser extends CriteriaValidator def parse ConditionGroup ): Try [String ] = { validate(group).map(_ => group.evaluate) } }
结论 就我个人而言,我认为OO与FP并不是势如水火的天敌,也无需发出“既生瑜何生亮”的慨叹,非得比出胜负。本文的例子当然仅仅是冰山一角地体现了OO与FP各自的优势。善于面向对象思维的,不能抱残守缺,闭关自守。函数式思维的大潮挡不住,也不必视其为洪水猛兽,反而应该主动去拥抱。精通函数式编程的,也不必过于炫技,夸大函数式思维的重要性,就好似要“一统江湖”似的。
无论面向对象还是函数思维,用对了才是对的。谁也不是江湖永恒的霸主,青山依旧在,几度夕阳红!